Note: Starting from this post, I will no longer be sharing any updates on Twitter or LinkedIn. All updates, like this one, will be posted here on this blog.
My work at UIUC, AlphaTrans: A Neuro-Symbolic Compositional Approach for Repository-Level Code Translation and Validation, has been accepted to appear at the FSE 2025 conference in the Research Papers track. This work was led by Ali Reza Ibrahimzada who is a PhD student at UIUC. Professor Reyhaneh Jabbarvand facilitated this project as a collaboration between her group and IBM Research. Our work presents an automated solution for translating entire code repositories from one programming language to another. We essentially use LLMs to generate these translations and apply a range of validation techniques to ensure the semantic equivalence of the generated code with the original code.
I am also particularly grateful to Professor Darko Marinov at UIUC for involving me in this project and for hosting me as a visiting student researcher at UIUC during the summer of 20241. Special mention also goes to Salman Abid, who is now a PhD student at Cornell University. Despite his busy schedule due to his preparations for moving to the US, he was regularly available to help me with challenges related to GraalVM and the Polyglot API, besides being an ear to me beyond the technical aspects of the project.
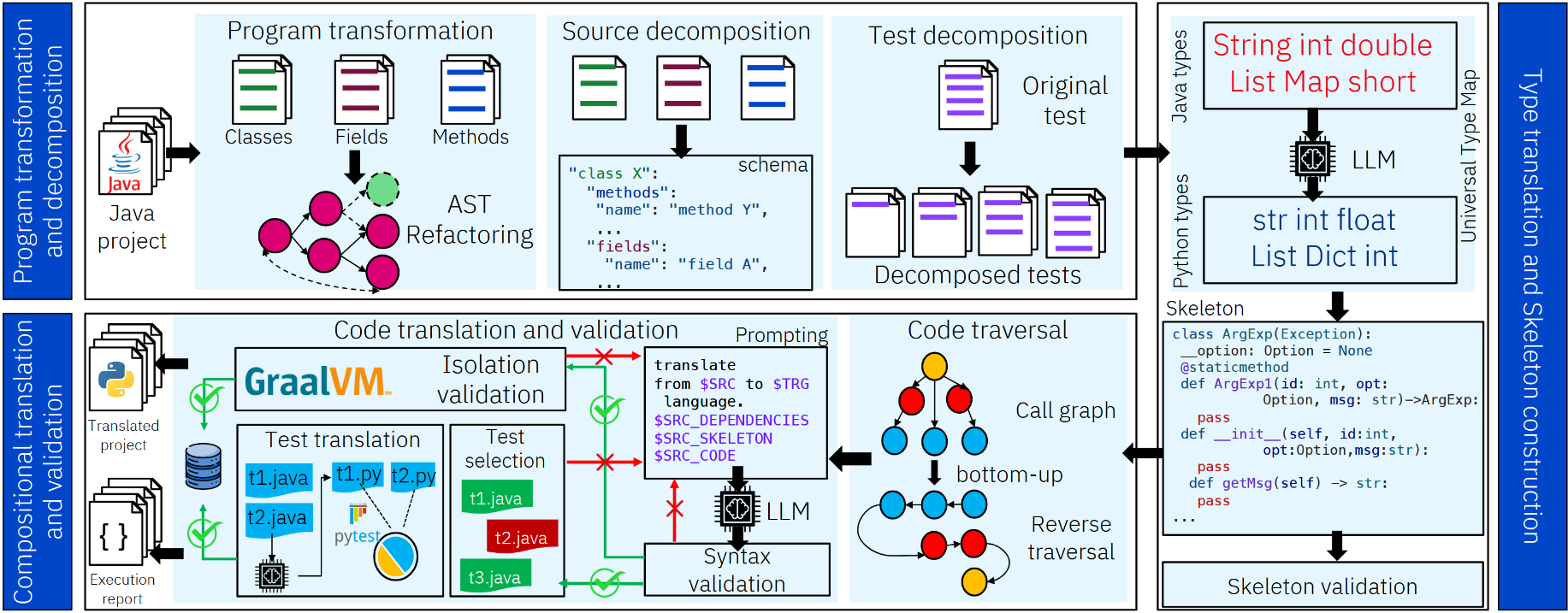
This project was my first big project. And big it was. I started working sometime in January last year and was still applying fixes to my system in December. We missed our planned ICSE 2025 deadline in August and submitted to FSE 2025 in September. Over more than 7 months since then, we submitted a rebuttal and then a major revision before finally hearing back in April. More importantly, this was the first time that I saw an actual gap, and that too a significant one, in existing literature, and that I worked on pretty much the cutting edge of research in the area. While work on code translation goes back to the 1960s, LLMs have brought renewed interest to it, with many notable papers demonstrating their potential in this context. However, previous work more or less remains limited to translating small snippets of code, and automated whole-project code translation continues to be a challenge. Advances in the area are valuable because code translation is a practical problem that software-based companies face on a large scale. Old technologies become obsolete, and it becomes increasingly difficult to find developers who can maintain legacy code. The challenge is huge for real code because the code is voluminous, spread across a large number of files, has complex inter- and intra-file dependencies, and often utilizes many third-party libraries. Either way, this is a fast-moving area, and indeed, just as we were trying to create the state-of-the-art, several related works2 were coming up as well.
We demonstrated our approach by translating several open-source Java projects to Python, and my particular contribution was to create a system for validating the Python translations of individual Java methods. It is natural to translate the test suite of the original Java project to Python and use the test suite to validate the translations. However, things are far from straightforward. First of all is the question of how one would validate the test translation itself — after all, there are no tests for the tests. The test code is indeed much simpler than the main code, at least in logical complexity, and one could manually validate the test translations. But even then, tests can call several methods in the main code, and all of them would have to be translated before any test could even be executed. In a setting where we wish to translate the code step by step, say a method-at-a-time, this postpones validation and makes it harder to localize and fix bugs. Bug localization becomes much easier if validation could be performed at each step so that we know which method exactly causes tests to fail. My system uses GraalVM and its Polyglot API to bridge Java tests and translated Python code. One can think of this as almost literally replacing the code of a Java method with its corresponding Python translation. Yes, some objects have to be passed between the two languages, and types have to be taken care of, but that is all engineering. The system is not perfect, but it works reasonably well even for real-world projects and caters to much more complicated types than those in recent related work. This particular aspect of the work is a follow-up on my initial efforts in creating such a validation system in my previous work, GlueTest3, which I carried out during 2023 with Salman and several other undergraduate students from around the world4 along with Professor Darko and Professor Saikat Dutta, who is now at Cornell University.
Code translation is an exciting topic because it encompasses a wide range of problems in software engineering, right from specifications (what is a correct translation without a notion of correctness?) to testing (how do we check for the correctness of a translation?), and from program repair (how do we fix bugs in a translation?) to refactoring (how do we make a translation more idiomatic?). There’s a long way to some of these answers, but with LLMs combined with traditional software engineering expertise, we seem to be slowly getting there. Maybe in the future, it wouldn’t matter what programming language you use, and you would have a universal translator between all programming languages so that you could use whichever suits your taste. Until then, let me go back to cursing Java while I try to work through my course project for a distributed software class.
-
My visit has featured in several posts on this blog, including this and this, but also implicitly in terms of my technical (like this or this) and philosophical (like this) insights from that time. Let’s see if I can continue writing in the upcoming summer as well 😉. ↩
-
A highly non-exhaustive list in no particular order includes this, this and this. ↩
-
This was as part of the UIUC+ Software Engineering Summer Research program. ↩