I wasn’t following the AI hype before I joined college1, and while I had heard of GitHub Copilot2, I didn’t think much of it. I had been programming for several years by then, and couldn’t imagine how AI could help me write code. I was not the only one skeptical; in particular, most educators still saw AI as another tool for plagiarism and were highly conservative regarding its use.
Fortunately for me3, my first programming and algorithms course at IISc did not shy away from such developments. My professor, Viraj Kumar, made Copilot an integral part of the course, focusing on two main aspects:
-
Writing good specifications that express our intent unambiguously, possibly using simple examples, to Copilot.
-
Reading and critiquing code produced by Copilot, to make sure it correctly reflects our intent.
As I will discuss in this blog post, these two aspects of working with AI have been instrumental in my own journey as a programmer and also an undergraduate researcher in software engineering. I will particularly focus on how Copilot has played the role of a collaborator and at times, a coach in helping me get started with undergraduate research. Of course, this was possible because of GitHub’s Student Developer Pack4.
Using Copilot to improve specifications
My first undergraduate research project came out of discussions with Professor Viraj about how Copilot often suggests code that does not pass even on the test cases provided in the prompt. What was more interesting was that in some cases where the top suggestion was wrong, one of the other suggestions would be correct5. This is not surprising for a language model trained to produce strings, not code, and for a system that evaluates it by treating its suggestions as merely strings and not as code with nuanced semantics. Note that our inputs to Copilot were incomplete Python function definitions with a docstring that included doctests, as shown in the below illustration, and we asked Copilot to write the body of the function.
def function_name(arg1: int, arg2: str) -> bool:
"""
Purpose of the function.
>>> function_name(1, "test") # doctest 1
True
>>> function_name(2, "test") # doctest 2
False
"""
Our first idea was to simply run all of Copilot’s suggestions through the provided test cases and filter out the ones that did not pass — and I built a simple VS Code extension to do this. One could first prompt Copilot to produce suggestions, and then trigger our extension to filter them. This was a good start, but we soon came across a more fundamental question. Could better specifications have helped Copilot produce correct code more confidently?6
It seemed that the lack of confidence in its suggestions — i.e., the suggestions were functionally different from each other — was due to the ambiguity in the specification itself. Even more importantly, it seemed that these very differences in the suggestions could be used to reveal the ambiguities in the specification. My programming and algorithms course had focused a lot on writing good purpose statements for functions, and both Professor Viraj and I were excited to see if we could use such findings to build a tool that would not only alert programmers about ambiguous specifications but also help students learn how to write better specifications in the first place. At the same time, this can also encourage students to think more deeply about given requirements and ask the right clarifying questions, which is a skill that is often overlooked in programming courses.
This took shape as a tool called GuardRails, which we eventually presented at the COMPUTE 2023 conference. The idea was rather simple7 — we would take all of Copilot’s suggestions, filter out the ones that did not pass the given test cases, and then run the remaining suggestions through several inputs8 to see if we could find an input where they behaved differently. If we did, this input, and potentially a class of similar inputs, would be a suspected source of ambiguity in the specification that we would then report to the user.
For instance, consider the following input to Copilot.
def common_letters(word1: str, word2: str) -> list[str]:
"""Return a list of letters common to word1 and word2.
>>> common_letters('cat', 'heart')
['a', 't']
>>> common_letters('Dad', 'Mom')
[]
"""
As you might be able to identify, there are many things which are unclear about this request. Does the order of letters in the output matter? If a common letter appears multiple times in both strings, should it appear multiple times in the output? Importantly, none of the doctests can clarify these. We observed that Copilot often produced suggestions that filled such ambiguities in different ways — and our tool could help identify these ambiguities by finding inputs (and usually the simplest such inputs) which could lead to different outputs under different interpretations.
Consider the following two suggestions for completing this function definition.
def suggestion1(word1: str, word2: str) -> list[str]:
return [c for c in word1 if c in word2]
def suggestion2(word1: str, word2: str) -> list[str]:
return [c for c in word2 if c in word1]
The fact that these two suggestions produce different outputs for the input strings ab and ba suggests an underspecification related to the order of letters in the output. Similarly, the following two suggestions differ in the treatment of duplicate letters, like when provided with the input strings aa and aa.
def suggestion3(word1: str, word2: str) -> list[str]:
return [c for c in word1 if c in word2]
def suggestion4(word1: str, word2: str) -> list[str]:
return [c for c in set(word1) if c in set(word2)]
The demonstration below shows this example in action. Our dataset lists several other interesting examples.

A quick demo of GuardRails. A free copy of our paper is available on arXiv. Note that our tool does not work presently because of changes in the Copilot VS Code extension, and an update is underway. If you would like to contribute, please reach out to me, and I would be happy to discuss.
From a logistical perspective, this was a time when LLMs were still new, and free APIs were not as common as they are now. We wanted to quickly experiment with our ideas without having to first seek funding to self-host an LLM or get access to a paid API. Copilot was not meant to be used this way, but making our tool work on top of it was indeed a nice hacky way to quickly implement our ideas and test them out. Today, of course, LLMs are more accessible, and Copilot itself provides many ways to smoothly integrate additional functionality, like through extensions and even agents.
Validating translated code at scale and accidentally learning Java
While working on GuardRails, Copilot’s role in my research was like that of a monkey in an animal behavior study. We analyzed its behavior, saw what it did correctly and what it did not, tried to understand why it did what it did, and then used that understanding to better guide its behavior. This was quite different from the colleague-like role it played in my next project, related to validating code translated from one programming language to another. I have talked about this work, called GlueTest, briefly in my previous blog post. I had the opportunity to co-lead this work with the supervision of Professor Darko from UIUC and Professor Saikat from Cornell, and we were essentially trying to build a testing framework to validate whether code produced after translating an existing code base (in our case, in Java) to another language (in our case, Python) is indeed a correct translation. As I also discussed in my previous blog post, this has a few interesting challenges.
Most serious projects have developer-written tests, and it is natural to translate the test suite in the source language to the target language and use that to validate the translated code too — but it’s usually not that simple! Test code can be voluminous and occasionally complicated — and how do we know if the tests themselves were correctly translated? Incorrect test translation can lead to false negatives — where the translated code is actually correct, but the tests fail because of incorrect translation, thus undermining confidence in the translated code — ore even worse, false positives, where the translated code is incorrect but the tests pass, thus creating serious quality issues in the translated code base.
The other big challenge is that while translation efforts are usually incremental9, tests often exercise too many parts of the code base at once, making it hard to translate small parts of the code base at a time and validate them. If larger parts of the code base are translated, it becomes harder to localize errors when a test fails, making debugging more time-consuming. Partial translation is a more practical approach that is followed in practice, where a project is translated fragment by fragment, and each fragment is validated before moving on to the next one. The following diagram illustrates this idea.
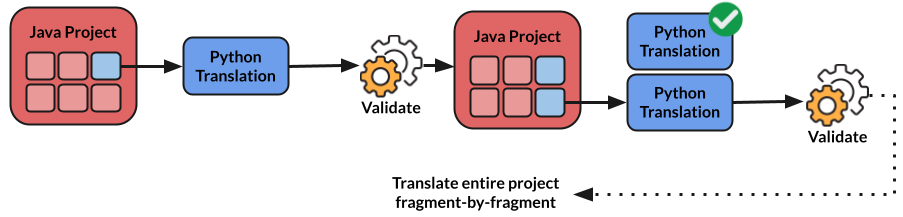
An illustration of the partial translation approach. The idea is a fragment-by-fragment translation of the project, validating each fragment before translating the next one.
Long story short — we proposed a framework to directly run tests in the source language on the translated code in the target language — with a glue layer that translates data on the boundary between the two languages. In our case of Java-to-Python translation, this meant that we would run the original Java tests, but redirect calls to the main Java code to the corresponding Python translation, which would then return the result back to the Java test. At the point where execution leaves Java and enters Python, we would convert the input Java objects to appropriate Python objects (like converting a Java List to a Python list). Similarly, when the execution returns from Python to Java, we would convert the output Python objects back to Java objects (like converting a Python str to a Java String). This intermediate conversion layer is what we call the glue layer — and it actually does a lot more than this, like maintaining pointer identity, propagating side effects, transmitting exceptions, and so on. The following example shows how this works in practice for a developer using our framework.
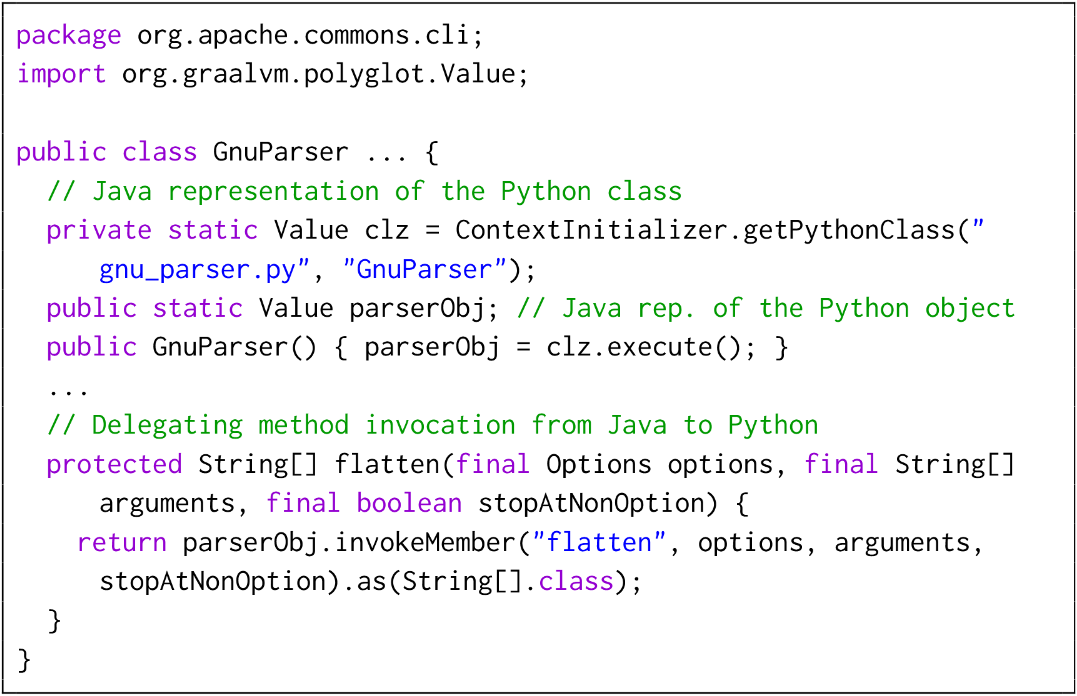
An illustration of our GlueTest approach. What is happening here is that we create a Python representation of every Java object, and when a Java test calls a method in the Java main code, we redirect that call to the corresponding Python representation, which implements the same method in Python. As the execution flows between the two languages, the glue layer converts objects between the two languages. A freely available preprint of our work is available here.
Where does Copilot come into this picture? In order to evaluate our approach, we manually translated two Java libraries10 to Python — and well, this was my first time writing Java code. Yet I managed to become one of the main contributors to the project, thanks to Copilot. I would translate the code class by class, and Copilot would give me a reasonably good template to start with. Usually, I would modify the translation for one of the methods in the class to fit my needs, and then Copilot would very quickly adapt to that style and structure. Of course, Copilot would make mistakes, especially in things with subtle differences between the two languages, but my work was limited to finding solutions to these tricky11 problems instead of doing the grunt work of writing obvious code. And in all of this, I found myself slowly picking up quite a significant amount of Java12. I am not saying that I am now a Java programmer, but I could see during my other projects and also some of my classes at University that my understanding of Java and its nuances has been coming in handy.
Conclusion
The bottom line here is that I can concretely see that Copilot makes me much faster at producing code. It does seem very magical, and at times, it might even feel like I am cheating my way through. But at the end of the day, it is another tool in addition to the plethora of linters, snippets, auto-completions, and other tools that our code editors have provided us for a long time. And like any of these tools, it is not a replacement for good programming practices13. As I discussed above, it is also not a replacement for actually learning to write code! I don’t think it is really a question anymore of whether or not we should use AI for programming — and so we should instead think more deeply about how we can use it effectively to complement our existing skills and tooling, what its limitations are, how far can we get around these limitations with additional infrastructure, and how we can use it to make coding more accessible not just to novices but even to experienced programmers who just want to have a little bit of fun!
New: This blog post was featured in the Summer 2025 edition of the GitHub Education Student Newsletter.
-
Even when I did become interested, I gave up on trying to keep up with the latest news only within a couple of months because it was simply too much too fast. Now, I only read up when something catches my attention or when I need to know something specific. ↩
-
Which had been released less than 4 months before, in June 2022, for the public. ↩
-
At least retrospectively. ↩
-
As a side note, I must acknowledge that the Student Developer Pack is a genius move by GitHub to get students hooked to Copilot and other tools. I cannot imagine working without Copilot now, and have decided to continue studying through grad school for profiting from a free GitHub Copilot Pro license 😉. ↩
-
We could press
Ctrl+Enterin VS Code to see the list of up to 10 top suggestions. ↩ -
Where confidence in a suggestion can be thought of as the fraction of times the same, or an equivalent, suggestion is produced by Copilot. If Copilot produces the same suggestion multiple times, we can interpret that Copilot is confident about that suggestion. ↩
-
And had been explored in somewhat other contexts before, like in this paper. ↩
-
To be precise, we performed differential fuzzing on every pair of these suggestions. This means that we would take two suggestions, and run them against the same set of test cases to find inputs where they produced different outputs. These inputs are selected randomly, based on the type of the arguments expected by the function, with several heuristics in place to ensure that common edge cases (like empty lists, negative numbers, single-character strings, etc.) are not missed. ↩
-
All-or-nothing translations have been attempted, but as Terekhov and Verhoef mention in their article, this has been disastrous in practice — from abandoning entire projects to even bankruptcies. ↩
-
And arguably more interesting. I plan to share some of the insights from these problems in future blog posts. ↩
-
This deserves another blog post, but I believe I could truly appreciate the beauty of object-oriented programming only after working with Java. This is not only about how nice the code looks but also about how it enforces a certain way of thinking about code and writing it. ↩
-
Neither is it an excuse for not adhering to responsible practices around security and fair use. Since Copilot is trained on publicly available code, it is important to ensure that we do not accidentally violate software licenses or copy code without proper attribution. Similarly, it is crucial to review and understand AI-generated code to avoid potential security vulnerabilities and ensure that sensitive information is not inadvertently exposed. ↩